基于边沿采样的 RS485 波特率自适应总线仲裁系统
方案选择
flowchart LR
%%{init: { "flowchart": { "curve": "basis" } } }%%
subgraph SCH1 [最为稳定]
direction LR
SCH1_M1(M1 32bitTMR)
SCH1_M2(M2 32bitTMR)
SCH1_SL(SL 32bitTMR)
SCH1_M1<-->SCH1_SL
SCH1_M2<-->SCH1_SL
end
subgraph SCH2 [最低成本]
direction LR
SCH2_M1(M1 16bitTMR)
SCH2_M2(M2 16bitTMR)
SCH2_SL(SL 16bitTMR)
SCH2_M1<-->SCH2_SL
SCH2_M2<-->SCH2_SL
end
subgraph SCH3 [鱼掌兼顾]
direction LR
SCH3_M1(M1 32bitTMR)
SCH3_M2(M2 32bitTMR)
SCH3_SL(SL 16bitTMR)
SCH3_M1<-->SCH3_SL
SCH3_M2<-->SCH3_SL
end
SCH1-->SCH2-->SCH3
| 选型 | Tmr6p | Tmr6 | TmrA | Tmr2 | 最为稳定 | 最低成本 | 最多堆料 |
|---|---|---|---|---|---|---|---|
| 460 | 3 | 6 | 三路 | ||||
| 4A0 | 4 | 4 | 12 | 4 | 一路 | 两路+六路 |
采样上限
| 分频系数 | 时钟频率 | 时钟周期 | 计数上限 | 计时上限 | 波特率 | 单字边沿 | 字节上限 |
|---|---|---|---|---|---|---|---|
| 1 | 240.000MHz | 004.166ns | × 0xFFFFFFFF | = 017.895s | × 300 | / 10 | = 00536 Byte |
| 2 | 120.000MHz | 008.333ns | × 0xFFFFFFFF | = 035.791s | × 300 | / 10 | = 01073 Byte |
| 4 | 060.000MHz | 016.666ns | × 0xFFFFFFFF | = 071.582s | × 300 | / 10 | = 02147 Byte |
| 8 | 030.000MHz | 033.333ns | × 0xFFFFFFFF | = 143.165s | × 300 | / 10 | = 04294 Byte |
| 16 | 015.000MHz | 066.666ns | × 0xFFFFFFFF | = 286.331s | × 300 | / 10 | = 08589 Byte |
| 32 | 007.500MHz | 133.333ns | × 0xFFFFFFFF | = 572.662s | × 300 | / 10 | = 17179 Byte |
| 64 | 003.750MHz | 266.666ns | × 0xFFFFFFFF | = 1145.324s | × 300 | / 10 | = 34358 Byte |
| 128 | 001.875MHz | 533.333ns | × 0xFFFFFFFF | = 2290.649s | × 300 | / 10 | = 68716 Byte |
该表格为 32 位计数器单个周期的采样上限,若实现溢出处理,理论上单帧数据不存在采样长度限制。
内存占用
| 特征字节 | (每字节)边沿个数 | 采样单位 | (每字节)采样长度 | 缓存能力 | 缓存大小 |
|---|---|---|---|---|---|
| 0x00 (N) | ↓↑ = 02 | × 4B (uint32_t) | = 08Byte | ||
| 0x00 (N) | ↓↑ = 02 | × 4B (uint32_t) | = 08Byte | ||
| 0x00 (N) | ↓↑ = 02 | × 4B (uint32_t) | = 08Byte | ||
| 0xFF (N) | ↓↑ = 02 | × 4B (uint32_t) | = 08Byte | ||
| 0xFF (O) | ↓↑ = 02 | × 4B (uint32_t) | = 08Byte | ||
| 0xFF (E) | ↓↑ = 04 | × 4B (uint32_t) | = 16Byte | ||
| 0x55 (N) | ↓↑ = 10 | × 4B (uint32_t) | = 40Byte | × 1KB | = 40KB = UINT32[10K] |
| 0x55 (O) | ↓↑ = 10 | × 4B (uint32_t) | = 40Byte | × 1KB | = 40KB = UINT32[10K] |
| 0x55 (E) | ↓↑ = 10 | × 4B (uint32_t) | = 40Byte | × 1KB | = 40KB = UINT32[10K] |
| 0xAA (N) | ↓↑ = 08 | × 4B (uint32_t) | = 32Byte | ||
| 0xAA (O) | ↓↑ = 08 | × 4B (uint32_t) | = 32Byte | ||
| 0xAA (E) | ↓↑ = 10 | × 4B (uint32_t) | = 40Byte | × 1KB | = 40KB = UINT32[10K] |
从端不存在并发场景,所以不需要分配很大的环形缓存,通常 1KB 即可满足要求。
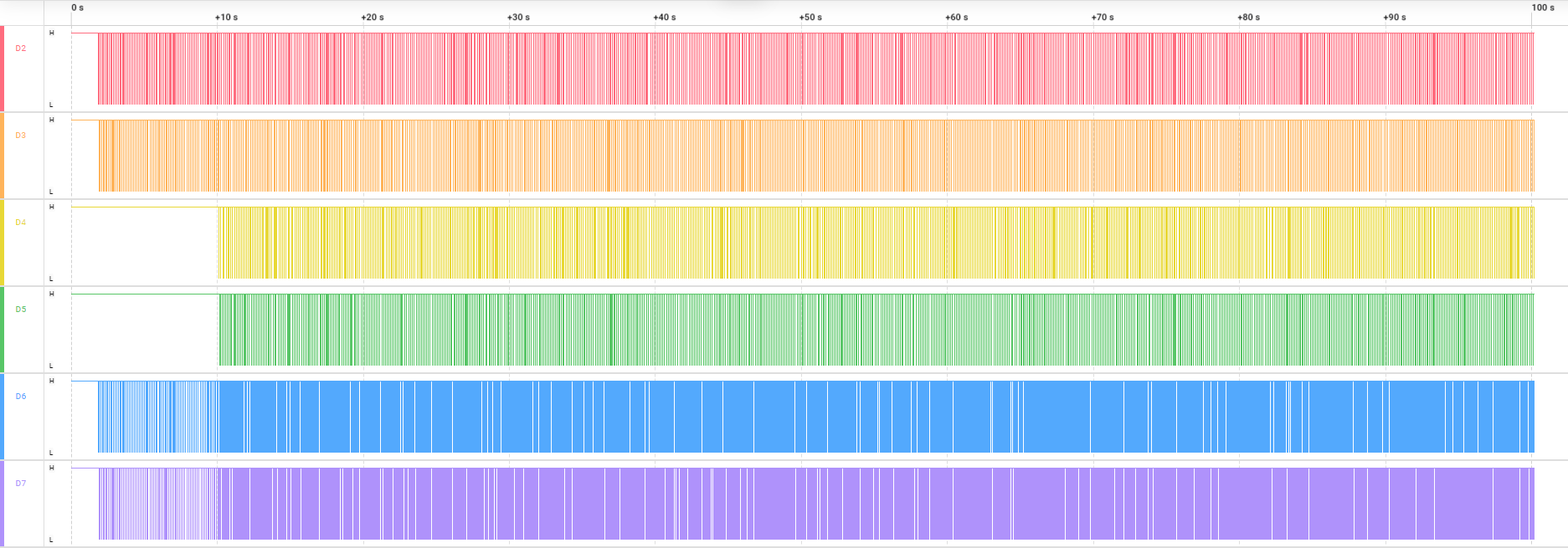
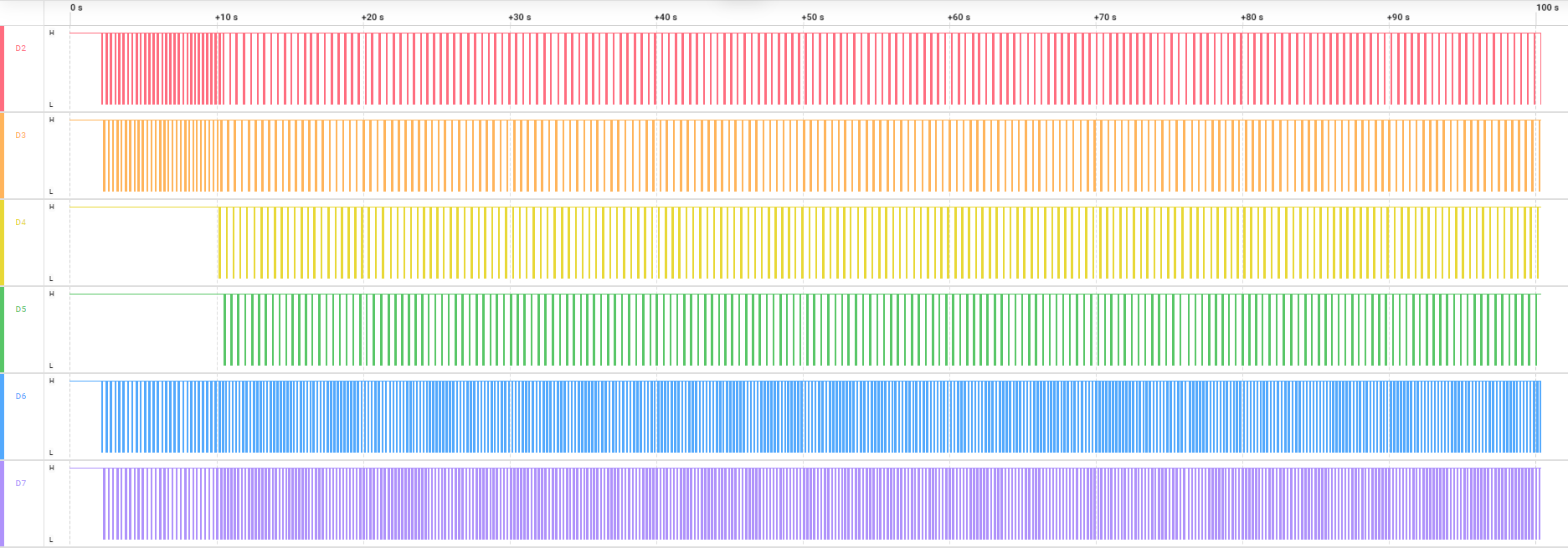
压力测试
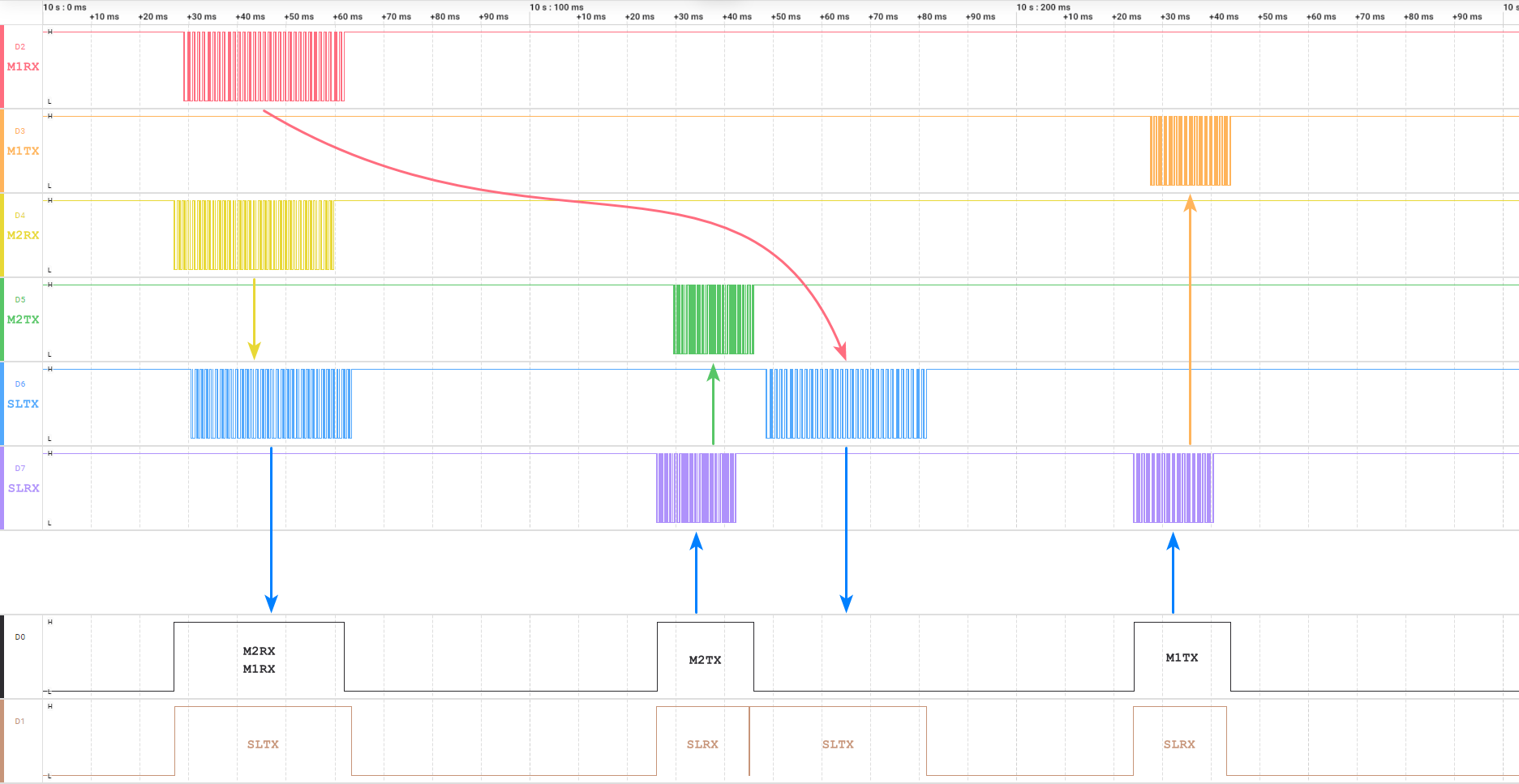
边界测试
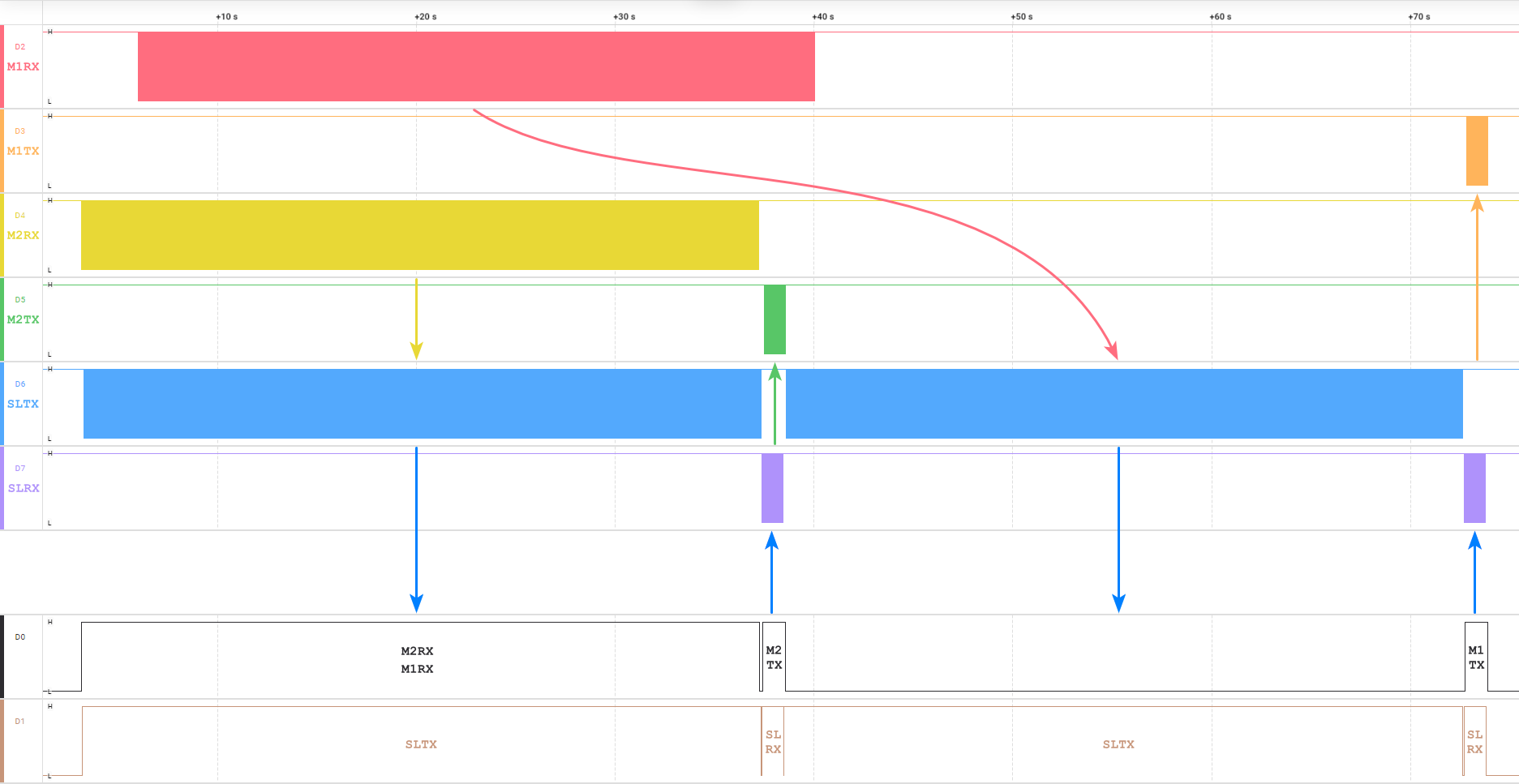
延后输出
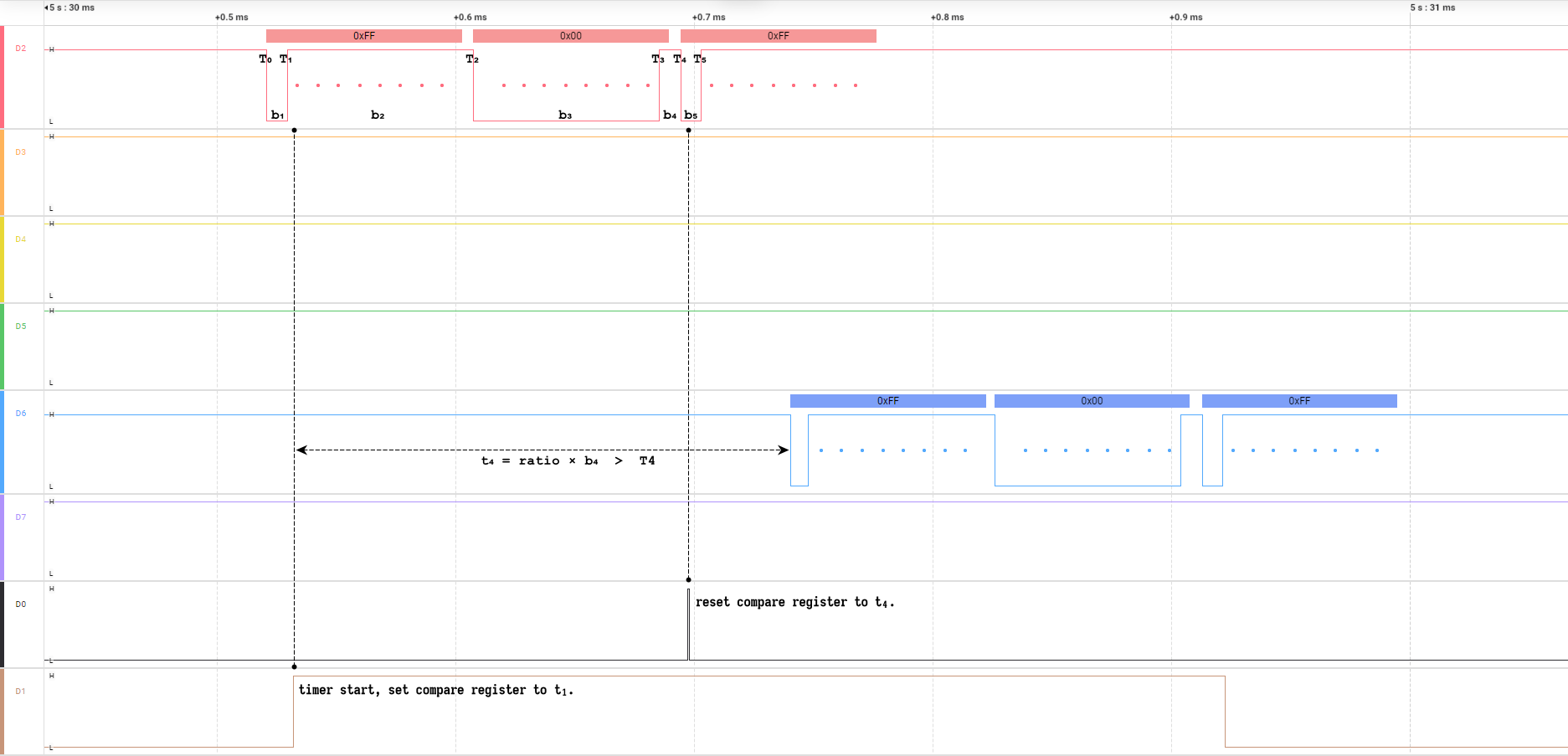
为了避免时序异常,在设置比较值 c 时通常在采样时刻 d₀ 的基础上加上一个偏置时间 t 来达到延后的效果,初始的 t₁ 由收到的第一个边沿 T₀ 和第二个边沿 T₁ 的间隔 b₁ 来确定,遵循以下公式:
其中 ratio 为延后倍率。
为了进一步降低转发延迟,在当前数据流的接收过程中如果出现了更小的边沿间隔 bᵢ,则将比较值重新设置为 ci,遵循的公式如下:
仅仅是这样还不行,还存在比较中断已被触发,此处的程序逻辑篡改比较值的风险,所以在超过一定数量的边沿 k 即 Tk 时刻之后就不能再去更新比较值了,因此还需满足:
其中 bₘᵢₙ 为当前数据流中可能出现的最小边沿间隔。
为什么不单纯使用延后若干个边沿个数的方式来控制呢?因为为了让单个的 0x00/0xFF 字节也能被正常透传,延后的边沿个数就不能超过两个,这样延后的时间太短,会出现比较中断已被触发,而新的边沿迟迟未到的情况,进而导致时序异常。
延时发送
两个主机并发抄读从机时,从端总线会非常繁忙,如果从机做得很垃圾的话(比如青岛某信的电表)则有可能无法正常响应:
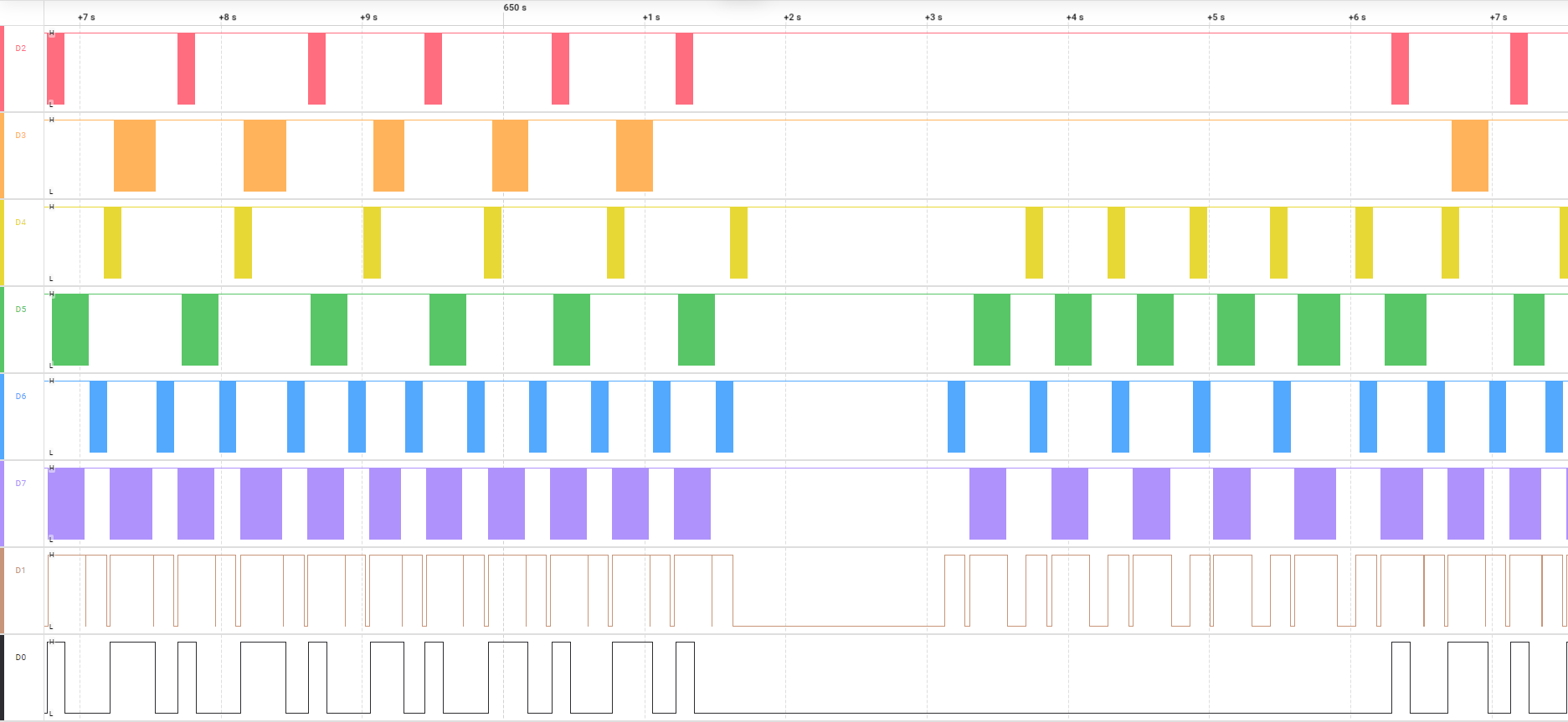
在两个数据转发包之间添加一定的延时(200ms)可以避免上述情况:
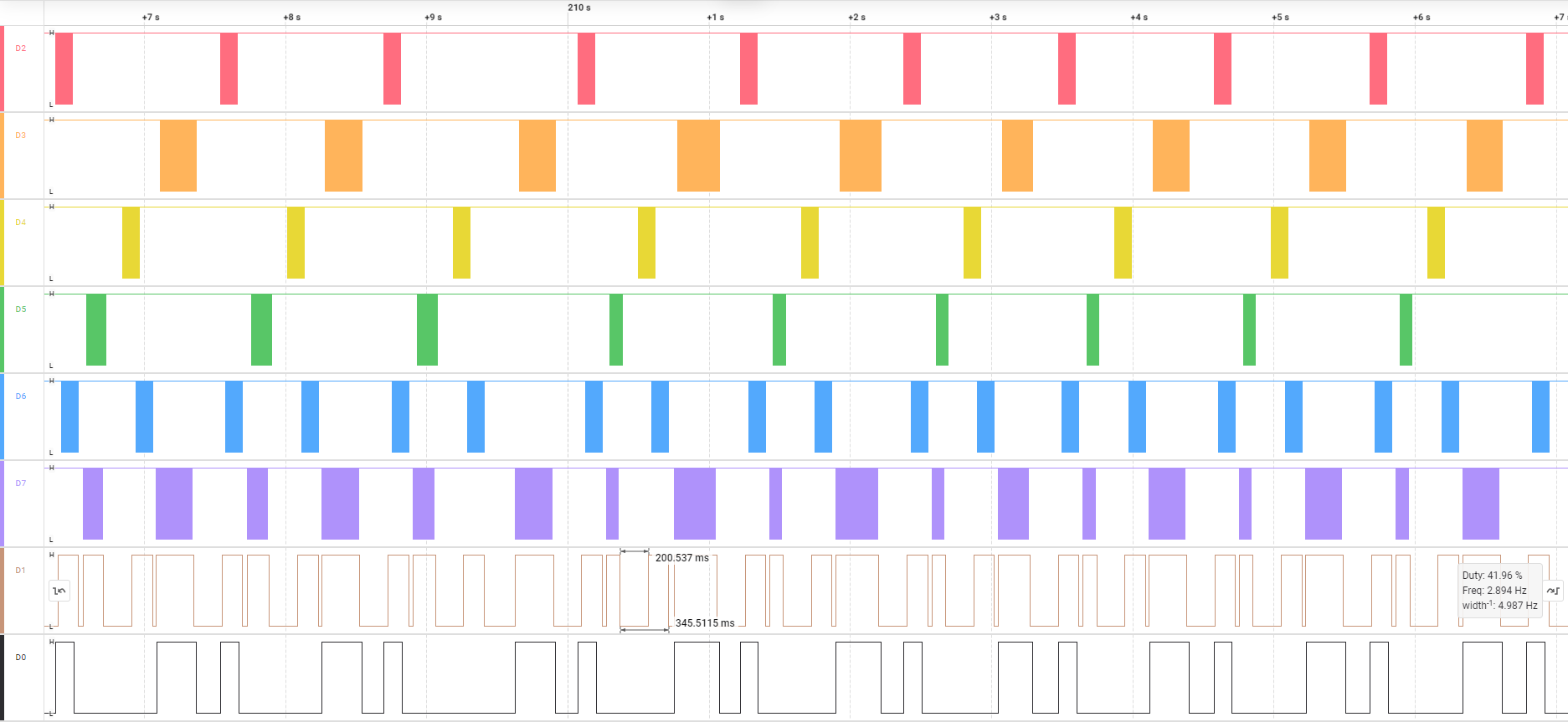
当总线上只接入一个主机时,即便不延时,也不会出现从机不响应的情况,这又怎么解释呢?这是因为主机在收到应答与发送下一包数据之间的间隔大约为 250 毫秒,间接实现了延时的效果:
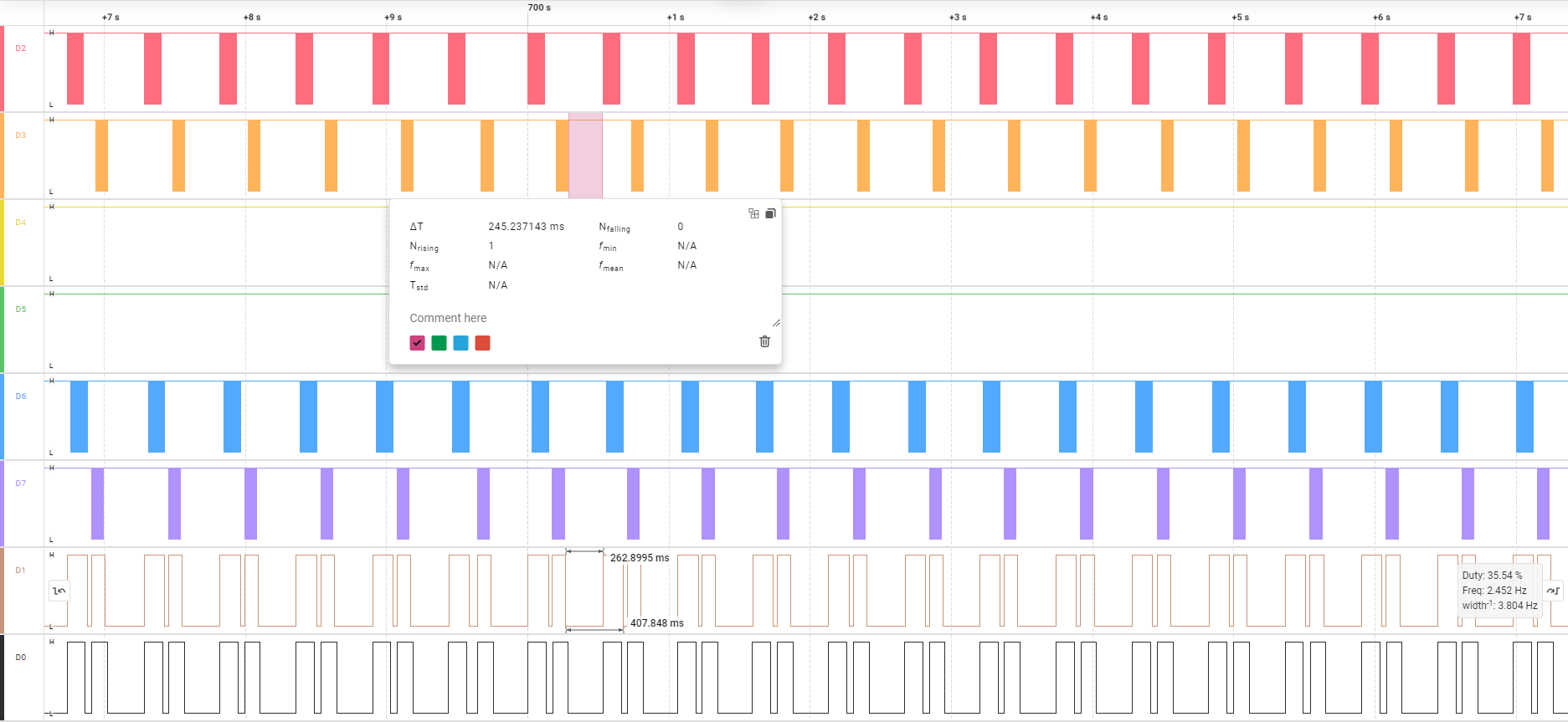
延时接收
从端发送完毕后建议延时 1 ~ 3 毫秒后再切至接收模式以避免收到噪声:
问题记录
(a)
现象描述: 单通道稳定,双通道乱码。
原因分析: 处理时间变长,波形畸变导致数据错误。
解决方式: 可以通过开启编译器优化来暂时解决该问题,但是要彻底防范则需要优化代码或进行补偿。
(b)
现象描述: 仲裁功能异常,若干秒后恢复。
原因分析: 设置比较值时,设置值小于当前值,因此要等溢出后下一轮才会触发中断处理函数并恢复。
解决方式:一是在设置时要再三检查,二是要进行超时处理。
(c)
现象描述: 以较低波特(无校验)发送 F0 F0 F0 F0 时总是超时。
原因分析: 该数据串的边沿间隔大于超时时间,导致误判。
解决方式:设置合理的发送超时时间,不应小于可能的最大边沿间隔,或者令超时时间支持动态自适应。
(d)
现象描述: 将 M1 和 M2 接到同一个 485 主机上来测试并发处理能力时,无法收到第二个应答或者出现自环现象。
原因分析: 当 M1 向主机应答时,此时 M1 处于 Tx 状态,而 M2 仍处于 Rx 状态,所以 M2 又会收到来自 M1 的应答,这样的话从端会依次转发来自 M2 的两个请求,在转发第二个本不应该存在的请求时,第一个请求的应答可能已经来了,这样就存在相撞的风险。
解决方式:使用两个 485 主机以不同的周期不断地发出请求,然后通过示波器观察两个主机的波形,必定存在波形重叠的时刻,以此判断设备支持并发处理能力。